
Introduction
Every digital transformation needs a data platform to transform data and master the challenges of Data Operations referred as DataOps to bring Data, Apps and Processes made by humans and machines together.
To make data accessible in real time to the right data scientists by decoupling business decisions from the underlying infrastructure, organizations need to remove bottlenecks from their data projects by implementing a Data Platform based on the best DataOps practices.
DataOps Defined
According to Wikipedia DataOps was first introduced by Lenny Liebmann, Contributing Editor, InformationWeek, in a blog post on the IBM Big Data & Analytics Hub titled “3 reasons why DataOps is essential for big data success” on June 19, 2014.
DataOps is an automated, process-oriented methodology, used by analytic and data teams, to improve the quality and reduce the cycle time of data analytics. While DataOps began as a set of best practices, it has now matured to become a new and independent approach to data analytics.
DataOps Re-Defined
Eckerson Group re-defines DataOps as follow, which we like so much:
“DataOps is an engineering methodology and set of practices designed for rapid, reliable, and repeatable delivery of production-ready data and operations-ready analytics and data science models. DataOps enhances an advanced governance through engineering disciplines that support versioning of data, data transformations, data lineage, and analytic models. DataOps supports business operational agility with the ability to meet new and changing data and analysis needs quickly. It also supports portability and technical operations agility with the ability to rapidly redeploy data pipelines and analytic models across multiple platforms in on-premises, cloud, multi-cloud, and hybrid ecosystems.” [1]
Take it easy: DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics, but needs a well designed Data Platform!
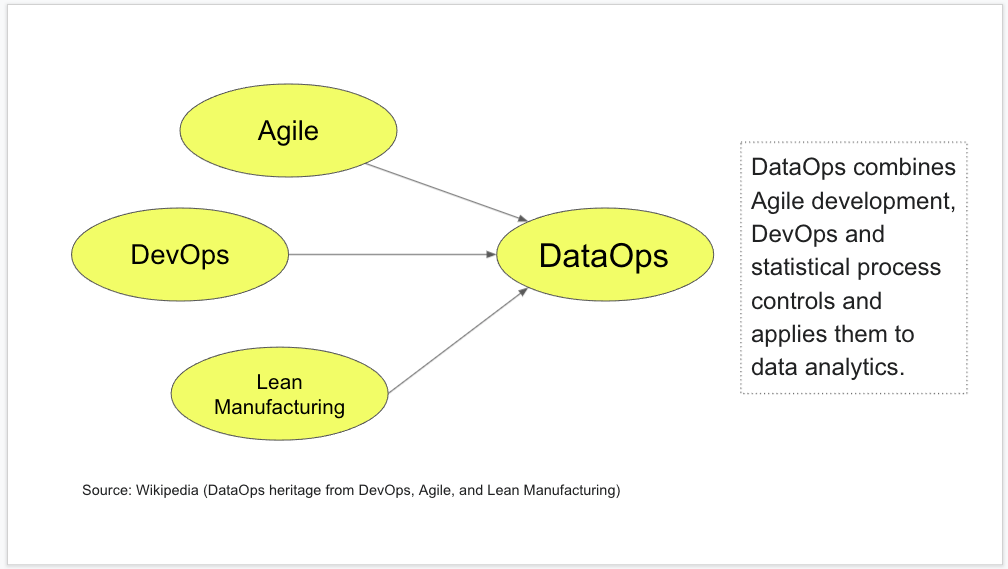
What is a Data Platform?
We define a Data Platform as the infrastructure with a minimal set, easy to extend base components to successfully deliver data-driven business outcomes with increased productivity and improved collaboration between data engineers, data and security operators through a governed Self-service operation with the highest possible automation.
That said, we believe a governed Self-service operation and automation is key to the success of most DataOps initiatives and needs a Platform to build Platforms. With Kubernautic Platform we made it happen to build a Data Platform based on Kubernetes, which is a Platform to build Platforms.
Kubernautic Data Platform: DataOps Orchestration on Kubernetes
Kubernautic Data Platform provides a cloud-native infrastructure with the base components as the foundation to run DataOps initiatives on Kubernetes through orchestration in a Self-service manner without the need to operate the platform on top of our Kubernautic offering.
Kubernautic Data Platform is designed to enable data scientists to deploy, implement and run their data analytic pipelines built on top of Apache Kafka, Cassandra, MQTT implementations, Spark and Flink with Jupyter notebooks to achieve the following goals:
- Gather and manage data in one secure place
- Build and share interactive dashboards
- Reduce time spent on errors and operational tasks
- Accelerate productivity through team collaboration
- Orchestrate your development and production pipelines for re-usability and security
- Unlock the full potential of DataOps without the need to operate the platform
- Create innovative data analytics and deliver intelligent business value
DataOps Needs a Culture made by People to build the Data Factory
Like DevOps, DataOps is mainly a principle to create and develop a strategy in your organisation to overcome the cultural obstacles to achieve higher agility by development and delivery of enterprise grade data pipelines to turn data into value through automation and the right processes and product design made by people to build the Data Factory!
Kubernautic Data Platform: The DataOps Data Factory
These days machines are assembled mostly by machines designed by people and complex processes in a data-driven world to deliver products in factories.
The following quote from Elon Musk describes the true problem and the solution to thinking of the Factory like a product.
“We realised that the true problem, the true difficulty, and where the greatest potential is — is building the machine that makes the machine. In other words, it’s building the factory. I’m really thinking of the factory like a product.” Elon Musk
With Kubernautic Data Platform we deliver a highly automated system to build a Data Factory for DataOps to build enterprise grade data-driven products and services on top of our Kubernautic Platform.
Some base components of Kubernautic Data Platform — which mainly provides the persistent layer of the platform — are presented through the following figure:

Automation and Self-service at the heart of Kubernautic Data Platform
Like our Kubernautic public offering, where developers can get instant access for free to Spot Namespaces on Kubernetes or B2B customers within minutes to a dedicated Kubernetes cluster managed by Rancher Cluster Manager, Kuberbautic Data Platform provides the same agile experience to access the Data Factory for data pipeline and model orchestration, test and deployment automation for data pipelines and analytic models to make decisions faster with high quality data governed across a range of users, use cases, architectures and deployment options.
According to Gartner’s Survey Analysis in March 2020 titled as “Data Management Struggles to Balance Innovation and Control” [2], only 22% of a data team’s time is spent on new initiatives and innovation.
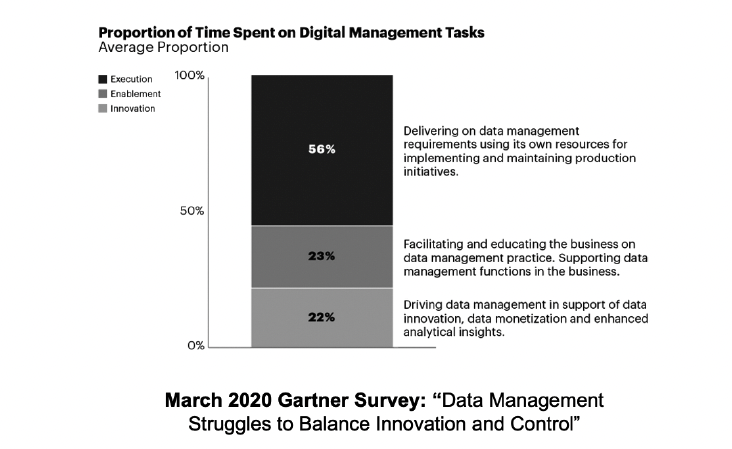
The Self-service capability of our Data Platform allows DevOps teams to provision Kubernetes clusters with DataOps base components within a few hours, not days or weeks waiting for IT operation teams to set-up the environment to explore, blend, enrich and visualize data. And exactly this Self-service capability of Kubernautic Data Platform boosts innovation by your DataOps projects.
DataOps and MLOps are almost the same, but …
MLOps stands for Machine Learning Operations and is almost the sibling of DataOps.
We love the great blog post by Fernando Velez — Chief Data Technologist by Persistent — in Data-Driven Business and Intelligence titled as:
“DataOps and MLOps: Almost, But Not Quite The Same” [3]
and invite you to read through Fernando’s view on this topic, which might help to keep your Data and Machine Learning initiatives accurate over time with NoOps!
Related resources
[1] DataOps: More Than DevOps for Data Pipelines (by Eckerson Group)
https://www.eckerson.com/articles/dataops-more-than-devops-for-data-pipelines
[2] Survey Analysis: Data Management Struggles to Balance Innovation and Control
https://www.gartner.com/en/documents/3982237/survey-analysis-data-management-struggles-to-balance-inn
[3] DataOps and MLOps: Almost, But Not Quite The Same https://www.persistent.com/blogs/dataops-and-mlops-almost-but-not-quite-the-same/
Kubernautic Data Platform for DataOps & MLOps was originally published in Kubernauts on Medium, where people are continuing the conversation by highlighting and responding to this story.
Mehr zu Kubernetes Services, Kubernetes Training und Rancher dedicated as a Service lesen unter https://blog.kubernauts.io/kubernautic-data-platform-for-dataops-mlops-bc719cde38a4?source=rss—-d831ce817894—4
Kommentarfunktion ist geschlossen